

Definamos “Ciencia de Datos”
Ahora todo es llamado “big data” y “ciencia de datos”. El problema es que no contamos con definiciones claras y comprobables.
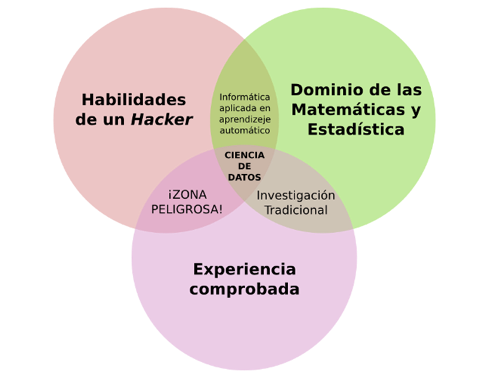
Se han realizado intentos para definir estos conceptos, en el caso de big data acostumbra mencionarse a las 3 Vs (volumen, variedad y velocidad), y en el caso de la ciencia de datos es común encontrarse con este diagrama.
El problema es que estas definiciones son abiertas; nombran algunos ejemplos (como el volumen), pero esencialmente dejan abierta la posibilidad de llamar cualquier cosa “big data” o “ciencia de datos”. Esto no es de sorpender, ya que a fin de cuentas son términos creados con propósitos de marketing.
Si alguna vez queremos llegar a una definición utilizable y deshacernos de todo el despliegue publicitario, debemos considerar una definición más precisa, inclusive cuando esto signifique hacerlo más exclusivo.
Big Data:
- Debe involucrar cómputo distribuido en múltiples servidores.
- Debe entremezclar gestión y procesamiento de datos.
- Debe ir más allá de las bases de datos relacionales y data warehouses.
- Debe permitir resultados que no estaban disponibles con los enfoques anteriores, o que llevarían sustancialmente mucho más tiempo (tiempo de ejecución o latencia).
Ciencia de Datos:
- Debe involucrar conocimientos de uno o más dominios (por ejemplo finanzas, medicina o geología).
- Debe tomar en cuenta aspectos computacionales.
- Debe incluir técnicas científicas tales como la prueba de hipótesis y la validación de resultados.
- Los resultados deben ser confiables.
- Debería involucrar más matemáticas y estadísticas que los enfoques anteriores.
- Debería incluir el aprendizaje automatizado (machine learning), inteligencia artificial o algoritmos de descubrimiento de conocimiento (knowledge discovery).
- Debería implicar la visualización y creación rápida de prototipos para el desarrollo de software.
- Debe satisfacer al menos uno de estos deberes en un nivel perturbador.
Pero todo esto está muy lejos de una definición adecuada, en parte debido al gran dinamismo que hay alrededor de estos conceptos.
Hay una gran cantidad de traslape que debemos tratar de comprender. Por ejemplo, la ciencia de datos no es sólo estadística porque está mucho más preocupada por cómo se estructura la información y cómo hacer el procesamiento de datos con mayor eficiencia computacional. Sin embargo, a menudo la estadística es mucho mejor para tomar en cuenta el conocimiento del dominio. En cambio, las personas procedentes del área de computación por lo general se preocupan muy poco sobre el conocimiento del dominio y la confiabilidad de sus resultados, son felices con lograr que los datos sean procesados.
Por último, pero no menos importante, pocas personas estarán a favor de una definición tan acotada y estricta. Porque esto implicaría que muchos tendrían que eliminar ese título de “científico de datos “ en su tarjeta de presentación – ¿y para qué morder la mano que nos alimenta? En mi caso, la mayor parte de lo que hago estrictamente no califica como «big data». Y aunque esto no disminuya el valor de mi trabajo, sí lo hace menos comercializables.

Esencialmente, esto es como un “acuerdo entre caballeros“ global: explotemos estas palabras mientras podamos, y luego pasamos a las siguientes.
Tal vez lo que deberíamos hacer es dejar estos términos a la gente de marketing para que los inflen hasta que exploten. En su lugar, deberíamos atenernos a los términos establecidos y mejor definidos:
- Cuando hagamos estadística, llamémosla estadística.
- Cuando hagamos aprendizaje no supervisado, llamémosle aprendizaje automático.
- Cuando nuestro enfoque es cómputo distribuido, llamémosle cómputo distribuido.
- Sigamos llamando gestión de datos a la gestión de datos.
En fin, lo que sea que hagas, utiliza el término preciso.
Por supuesto, en ocasiones tendremos que entrar en el juego del «buzzword bingo», no podemos evitarlo. Pero cuando podamos, seamos más precisos.
También debemos ser más cuidadosos con el uso del adjetivo «disruptivo». Mientras lo que hagamos sea “negocios como de costumbre “, y se base en software disponible comercialmente, no va a ser disruptivo. En realidad, lo que buscan las empresas no es big data ni ciencia de datos. Lo que buscan son resultados disruptivos, lo cual requiere hacer las cosas de manera radicalmente distinta.
Ser un científico de datos
Esta profesión empezó a ser demandada desde el 2013 debido al gran avance de la tecnología. En esta profesión no se es un analista de datos convencional, que sólo suele mirar los datos obtenidos de una única fuente. Un científico de datos es parte analista, parte artista. Su trabajo consiste en obtener las respuestas para preguntas o problemas que se plantean en negocios, universidades, en áreas de investigación científica: física, matemáticas, energía, ecología, etc.
Entre las habilidades que requiere un científico de datos están:
- Saber extraer los datos independientemente de su fuente (como ya expusimos al principio, éstas pueden ser desde las proporcionadas por un experimento o inclusive de la observaciones de fenómenos en la naturaleza).
- Saber limpiar los datos para eliminar aquello que distorsiona los mismos.
- Dominar la técnicas de procesamiento de datos usando diferente métodos estadísticos (inferencias estadística, modelos de regresión, pruebas de hipótesis, etcétera).
- Diseñar nuevas pruebas o experimentos en caso de ser necesario.
- Visualizar y presentar gráficamente (cualitativa y cuantitativamente) los datos y resultados.
Entonces, un científico de datos deberá ser capaz de tener sólidos conocimientos matemáticos, estadísticos e informáticos. Y lo mejor de todo, en tiempos actuales este científico es la persona más requerida en cualquier lugar del planeta.
Algunos códigos muy útiles
Programa R. (http://www.r-project.org) Es un software para el análisis estadístico de datos. Posee un lenguaje de comandos propio que lo dota de un potencial singular (aunque hay interfaces gráficas que permiten la realizar la mayor parte de las tareas a golpe de ratón), y es, sobre todo, un proyecto de colaboración a nivel mundial.
Al descargarlo e instalarlo se tiene acceso al programa, y a algunas aplicaciones sencillas de estadística y gráficos.
Programa Python.(https://www.python.org) Es un lenguaje de escritura independiente de plataforma y orientado a objetos, preparado para realizar cualquier tipo de programa, desde aplicaciones Windows a servidores de red o incluso, páginas web. Es un lenguaje interpretado, lo que significa que no se necesita compilar el código fuente para poder ejecutarlo, lo que ofrece ventajas como la rapidez de desarrollo e inconvenientes como una menor velocidad.
Posee una sintaxis muy visual, gracias a una notación con márgenes de obligado cumplimiento. En muchos lenguajes, para separar porciones de código, se utilizan elementos como las llaves o las palabras clave “begin” y “end”. Para separar las porciones de código en Python se debe tabular hacia dentro, colocando un margen al código que iría dentro de una función o un bucle. Esto ayuda a que todos los programadores adopten unas mismas notaciones y que los programas de cualquier persona tengan un aspecto muy similar.
Mathematica Wolfram.(https://www.wolfram.com/mathematica/trial/) Es un programa que permite hacer cálculos matemáticos complicados con gran rapidez. Es como una calculadora gigante a la que no sólo podemos pedirle que haga cálculos numéricos, sino que también derivadas, cálculo de primitivas, representación gráfica de curvas y superficies, etcétera.
El lenguaje de Mathematica Wolfram integra muchos aspectos del análisis de datos estadísticos, desde obtener y explorar datos hasta construir modelos de alta calidad y deducir las consecuencias. Ofrece varias maneras de obtener datos, comenzando con fuentes de datos integradas, importando desde una variedad de formatos de archivo o conectándose a bases de datos. El procesamiento básico, incluyendo el cálculo de cantidades estadísticas, suavizado, prueba y visualización, proporciona un primer nivel de análisis.
Es importante que antes de realizar cualquier prueba, con un programa informático, nos aseguremos de conocer en profundidad cómo se maneja el programa; este primer paso ha de considerarse básico para aplicar correctamente las pruebas. Existen muchos programas informáticos en el mercado, comerciales y de distribución libre. Su grado de bondad no depende esencialmente de su precio, con toda seguridad el mejor de todos es de distribución libre, aunque exige invertir mayor tiempo en su adiestramiento.
¿Qué se pretende con la ciencia de datos?
Todo lo que nos rodea contiene datos de todas clases y sabores, con lo que su eminente análisis es crucial. Estamos en una nueva era, la de estudiar datos con una alta precisión y exactitud -dos conceptos muy diferentes entre sí. En esta fase, la nueva generación de programas computacionales jugará un papel crucial en la ya conocida era del “big data”, donde la gestión y análisis de enormes volúmenes de datos que no pueden ser tratados de manera convencional superan la capacidad del software habitual para ser manejados y gestionados.
Te esperamos en los siguientes artículos en donde hablaremos mas acerca de estos temas, los cuales hoy en día son de vital importancia en el mundo de la tecnología.



