

¿Te gustaría aprender desde cero a trabajar con Apache Kafka, uno de los sistemas de procesamiento de datos en tiempo real más utilizados en el mundo?
Tenemos el curso que necesitas. ¡Haz clic aquí!
Apache Kafka es, como decíamos una plataforma de datos de tipo distribuido. Se trata de una herramienta que, originalmente fue diseñada para usar en LinkedIn para ayudar en el control de millones de mensajes dentro de la propia aplicación. De ahí se trasladó su uso a otras empresas, principalmente en servicios de chat y mensajería, para el procesamiento de grandes cantidades de datos.
No obstante, Apache Kafka puede ser usado para otros propósitos. Así, también nos encontramos con se trata de una plataforma de procesamiento y almacenamiento de datos que, al basar su arquitectura en eventos, puede usarse para mejorar la automatización de determinados procesos comerciales y productivos.
¿Cuáles son las ventajas de Kafka?
Código abierto
Significa que el código fuente de Kafka está a disposición gratuita de quien quiera usarlo, modificarlo y distribuir su propia versión con cualquier fin. No hay ni licencia ni restricciones. Otra ventaja de Kafka es que recibe la colaboración y las aportaciones de una comunidad mundial de desarrolladores. Por eso ofrece una amplia gama de conectores, complementos y herramientas tanto de monitorización como de configuración como parte de un ecosistema que se amplía de manera constante.
Escalabilidad y rapidez
Kafka no solo se escala conforme aumentan los volúmenes de datos, sino que también reparte esos datos por toda la empresa en tiempo real. Otro punto fuerte de Kafka es que, al ser una plataforma distribuida, el procesamiento se divide entre varias máquinas físicas o virtuales. Eso reporta dos ventajas: una, con un poquito de trabajo, admite el escalado horizontal para añadir máquinas cuando hace falta más potencia de procesamiento o espacio de almacenamiento y, dos, ofrece fiabilidad porque la plataforma se sigue ejecutando aunque falle alguna máquina. No obstante, esta característica de Kafka puede resultar muy difícil de gestionar a escala.
¿Cuáles son las ventajas de Apache Kafka?
Estas son algunas de las ventajas que tiene Apache Kafka en su uso e implementación en los procesos comerciales de las empresas:
- Rendimiento: Apache Kafka es capaz de manejar un gran volumen de datos a gran velocidad. Así, por ejemplo, Kafka, en aplicaciones de mensajería, puede manejar millones de mensajes por segundo.
- Escalabilidad: Al tratarse de una plataforma distribuida, Kafka es fácilmente escalable. Así, con solo añadir nuevos nodos al clúster de datos es suficiente para mejorar el alcance y el procesamiento de los datos.
- Baja latencia: Apache Kafka es capaz de entregar el gran volumen de datos que maneja con una latencia, es decir, un retraso, de tan solo 2 milisegundos.
- Almacenamiento: Los datos que se manejan con Apache Kafka se almacenan de manera segura. Y es que, al tratarse de una plataforma distribuida, es tolerante a fallos, ya que la información se comparte en distintos nodos. Si uno de ellos falla, hay otros que tienen también la misma información y se puede recuperar.
- Disponibilidad: Con Apache Kafka se pueden extender los clústeres para hacer que estén disponibles en distintos puntos geográficos.
¿Cómo funciona Kafka?
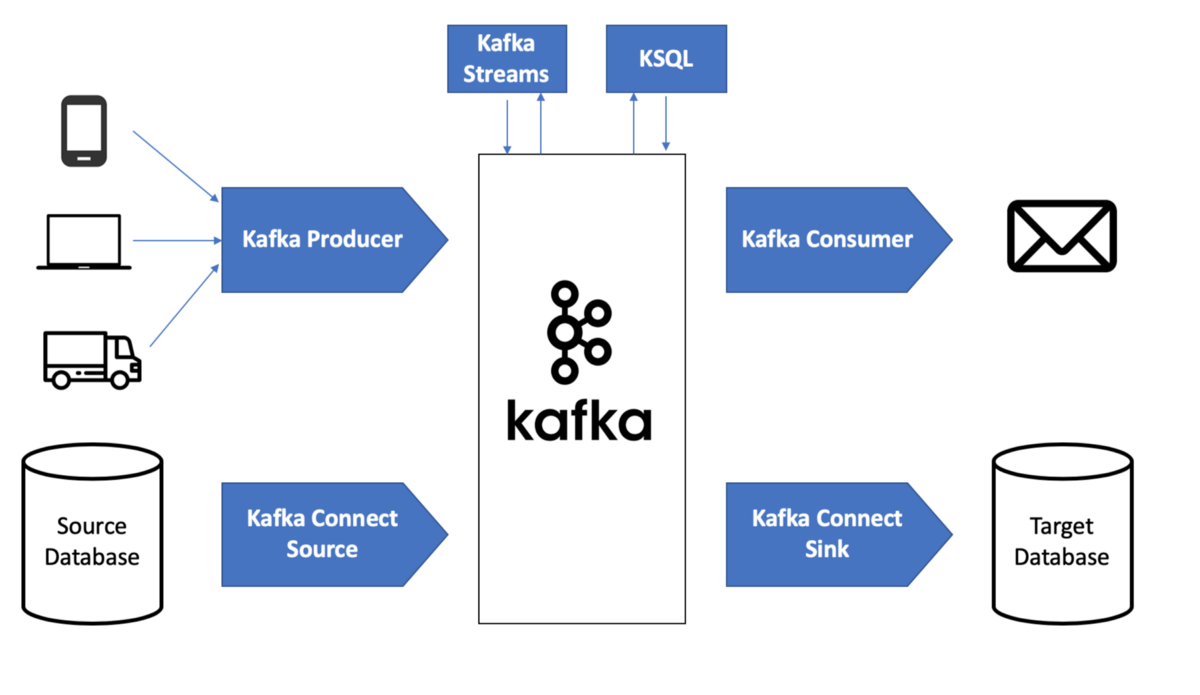
Kafka permite procesar eventos de streaming por medio de cinco funciones clave:
Publicar
Las fuentes de datos pueden publicar o colocar flujos de eventos de datos en temas de Kafka o grupos de eventos de datos parecidos. Por ejemplo, puedes publicar los flujos de datos de un dispositivo de Internet de las cosas (como un router de red) en una aplicación que, gracias al mantenimiento predictivo, calcula cuándo es probable que falle dicho dispositivo.

https://empleos.tecgurus.net/
Consumir
Las aplicaciones se pueden suscribir a temas de Kafka o extraer datos de ellos y procesar el flujo de datos resultante. Por ejemplo, una aplicación puede extraer los datos de los flujos de varias redes sociales y analizarlos para determinar el cariz de las conversaciones online sobre una marca.
Procesar
La API de Kafka Streams puede funcionar como procesador de streaming: consume los flujos de datos procedentes de los temas y produce flujos de datos que se insertan en ellos.
Conectar
También puedes crear conexiones reutilizables de producción o consumo que vinculen los temas de Kafka con las aplicaciones disponibles. Puedes usar cientos de conectores, como los que vinculan con servicios tan esenciales como Dataproc o BigQuery, entre otros.
Almacenar
Apache Kafka proporciona un espacio de almacenamiento duradero. Kafka puede funcionar como fuente de información veraz, ya que distribuye los datos por los distintos nodos para que el despliegue ofrezca alta disponibilidad tanto en un único centro de datos como en diferentes zonas de disponibilidad.
Te invitamos a ver todos los artículos que tenemos para ti, coméntanos que tal te pareció este artículo y compártelo con más personas.
¿Te gustaría aprender desde cero a trabajar con Apache Kafka, uno de los sistemas de procesamiento de datos en tiempo real más utilizados en el mundo?
Tenemos el curso que necesitas. ¡Haz clic aquí!




